T4. XML, Json y otras hierbas¶
XML¶
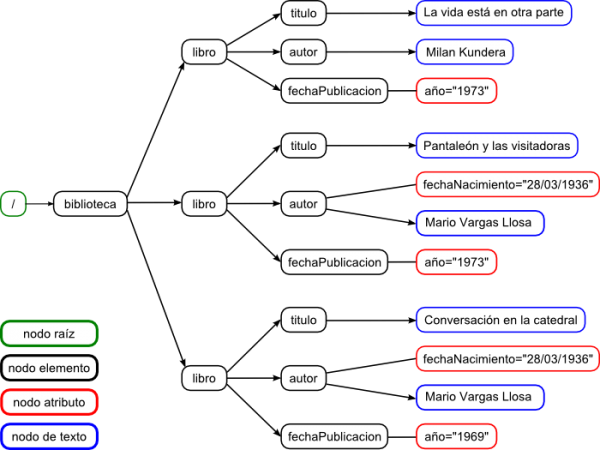
Ejercicio¶
Dado el esquema anterior, crea el XML que lo implemente.
DTD¶
El Documento de Definición de Tipos o DTD (Document Type Defintion) por sus siglas inglesas:

Creación de un DTD y su incorporación al XML.
Elementos:¶
EMPTY: nadaPCDATA: texto en claroANY: cualquier tipo- nodos: elementos de otro tipo (complejos)
Cantidades:
- Nada -> 1
- ? -> 0 o 1
- + -> 1 o más
- * -> 0 o más
- | -> enumerado
Xpath¶
Introducción a Xpath para realizar consultas sobre diccionarios XML
Herramientas¶
Con herramientas On-line xpather.com, xpath-tester y codebeauty, o creando las nuestras propias con Java o JS por ejemplo.
Funciones¶
- Suma:
sum(//price)(valor redondeado). - Cuenta:
count(//title)
En Xpath v2:
- Mínimo:
min(//book/price) - Máximo:
max(//book/price) - Media:
avg(//book/price)
Referencias¶
Desde Java¶
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.*;
public class JugandoConXPath1 {
public static void main(String[] args) {
String path = "./src/main/resources/";
String xml = path +"libros.xml";
Document doc = config( xml );
if (doc == null) {
System.out.println("No se encontro el archivo");
System.exit(1);
}
try {
//
// ... aquí las consultas usando las funciones:
// - printListXpath() -> obtiene la lista de nodos
// - printNumberXpath() -> obtine el número de nodos
//
} catch (XPathExpressionException xpee) {
System.out.println("Error en expresión XPath suministrada");
xpee.printStackTrace();
}
}
/** Nos genera un documento xml para analizarlo (parsearlo)
*
* @param xml La ruta completa al archivo
* @return el documento
*/
public static Document config(String xml){
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(true); // never forget this!
try {
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(xml);
return doc;
} catch (ParserConfigurationException pce){
System.out.println("No pudo configurar XPath");
} catch (SAXException saxe) {
System.out.println("Error genérico de XML");
saxe.printStackTrace();
} catch (NullPointerException npe){
System.out.println("Has pasado una expresión nula (NULL)");
} catch (IOException ioe){
System.out.println("No se pudo abrir el archivo fuente XML");
}
return null;
}
/** Imprime el número que devuelve la expresión solicitada.
*
* @param doc El documento xml generado con JugandoConXPath1.config( xml )
* @param expresionXpath La expresión Xpath
* @param titulo El texto que representa
* @throws XPathExpressionException En caso de error de expresión
*/
public static void printNumberXpath(Document doc, String expresionXpath, String titulo) throws XPathExpressionException {
XPathFactory xpathfactory = XPathFactory.newInstance();
XPath xpath = xpathfactory.newXPath();
System.out.printf("%s => %1.0f%n%n%n", titulo, xpath.compile(expresionXpath).evaluate(doc, XPathConstants.NUMBER) );
}
/** Imprime la lista de nodos seleccionados por la expresión Xpath.
*
* @param doc El documento xml generado con JugandoConXPath1.config( xml )
* @param expresionXpath La expresión Xpath
* @param titulo El texto que representa
* @throws XPathExpressionException En caso de error de expresión
*/
public static void printListXpath(Document doc, String expresionXpath, String titulo) throws XPathExpressionException {
System.out.printf("%s -> Xpath['%s']:%n", titulo, expresionXpath);
NodeList nodes = getNodeList(doc, expresionXpath);
printNodes(nodes);
}
private static void printNodes(NodeList nodes) {
for (int i = 0; i < nodes.getLength(); i++) {
System.out.printf(" - %s%n", nodes.item(i).getNodeValue());
}
System.out.println("\n");
}
private static NodeList getNodeList(Document doc, String expresionXpath) throws XPathExpressionException {
XPathFactory xpathfactory = XPathFactory.newInstance();
XPath xpath = xpathfactory.newXPath();
XPathExpression expr = xpath.compile( expresionXpath );
Object result = expr.evaluate(doc, XPathConstants.NODESET);
NodeList nodes = (NodeList) result;
return nodes;
}
}
Desde Javascript¶
const paragraphCount = document.evaluate(
"count(//p)",
document,
null,
XPathResult.ANY_TYPE,
null,
);
console.log(
`This document contains ${paragraphCount.numberValue} paragraph elements.`,
);
XQuery¶
Lenguaje de consultas “similar” a SQL que se apoya en Xpath para operar sobre XML
Validación con XSD¶
Para validar XML utilizaremos esquemas XSD
Herramientas¶
Referencias¶
Feeds: RSS y Atom¶
- ¿Qué es el RSS?, ¿cómo funciona? y ejemplo de dtd.
- ¿Qué es el Atom? RFC4287.
Json¶
¿Qué es el formato json?
El análisis de json.
Nativo (javascript)¶
json ➡️ objeto: miObjeto = JSON.parse(json_datos);
objeto ➡️ json: JSON.stringify({ x: 5, y: 6 })
Referencias¶
MariaDB y XML¶
Exportamos una base de datos:
mariadb-dump -u {{usuario}} -p{{password}} --xml db_alumnos > backup.xml
Exportamos una tabla o consula:
mariadb -u {{usuario}} -p{{password}} --xml -e 'USE alumnos; SELECT * FROM alumnos;' > backup_tabla_alumnos.xml
O incluso más granular mediante expresiones regulares:
mariadb -u {{usuario}} -p{{password}} --xml -e 'USE alumnos; SELECT * FROM alumnos WHERE apellidoPadre RLIKE ".*e.*e.*";' | tee backup_tabla_alumnos_o-o.xml`
MariaDB y Json¶
JSONis an alias forLONGTEXT COLLATE utf8mb4_binintroduced for compatibility reasons with MySQL's JSON data type. MariaDB implements this as a LONGTEXT rather, as the JSON data type contradicts the SQL:2016 standard, and MariaDB's benchmarks indicate that performance is at least equivalent.Fuente: Oficial
Dado que venimos trabajando con “los Json” como documentos y el tamaño de hasta 4GB cobra sentido que este tipo de operaciones las referenciemos como operaciones sobre documentos (de ahí el nombre de bases de datos documentales).
Funciones JSON¶
Funciones JSON disponibles en MariaDB:
JSON_VALID(): Válida el documento.sql SELECT JSON_VALID(campo_del_documento) FROM tabla;JSON_EXTRACT(): Extrae el valor (escalar, objeto o array) de un atributo. Para operaciones con diccionarios obtenemos el valor para la clave. Si hubiera claves repetidas, sólo obtendríamos el primer valor.sql SELECT campo_n, JSON_EXTRACT(campo_del_documento, '$.atributo') FROM tabla;JSON_QUERY(): Devuelve un objeto o array, o NULL si es un escalarsql SELECT campo_n, JSON_QUERY(campo_del_documento, '$.atributo') FROM tabla;JSON_VALUE(): Devuelve un valor ESCALAR o un NULL si no es escalar.sql SELECT campo_n, JSON_VALUE(campo_del_documento, '$.atributo') FROM tabla;
Ejercicio¶
Vamos a jugar con Json en MariaDB gracias a OneCompiler
1. Ejercicio básico sencillo¶
CREATE TABLE productos (
id INT AUTO_INCREMENT PRIMARY KEY,
nombre VARCHAR(100),
detalles JSON
);
INSERT INTO productos (nombre, detalles) VALUES
('Teclado', '{"codigo":101,"precio":1200,"tags":["periferico","gaming"]}'),
('Ratón', '{"codigo":102,"precio":850,"disponible":false}'),
('Monitor', '{"codigo":103,"precio":22000,"tamaño":[24,27]}'),
('Tarjeta SSD','{"codigo":104,"precio":15000,"esNVMe":true}');
Resuelve:
- Muestra el nombre y precio de los productos almacenados
- Muestra sólo los que cuesten más de 1000 €
- Muestra sólo los que sean discos NVME (pista “esNVME” = true)
- Obten la lista de tamaños del producto ‘Monitor’
2. Uno de arrays¶
SET @documento = '[0, "b", ["2a", "2b"]]';
Obten:
- El elemento segundo
- El tercero
- El primer elemento del tercero, el 3.1.
3. El oficial de mariadb¶
Vamos a crear la tabla del ejemplo:
# -- Creación de tabla con atributo JSON
CREATE TABLE locations (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
type CHAR(1) NOT NULL,
latitude DECIMAL(9,6) NOT NULL,
longitude DECIMAL(9,6) NOT NULL,
attr JSON,
PRIMARY KEY (id)
);
# -- Consulta de descripción de la tabla
DESCRIBE locations;
# -- O el create (para copiar y pegar)
SHOW CREATE TABLE locations;
# -- Añadimos registros
INSERT INTO locations (type, name, latitude, longitude, attr) VALUES
('R', 'Lou Malnatis', 42.0021628, -87.7255662,
'{"details": {"foodType": "Pizza", "menu":
"our-menu"},
"favorites": [{"description": "Pepperoni deep dish", "price": 18.75},
{"description": "The Lou", "price": 24.75}]}');
INSERT INTO locations (type, name, latitude, longitude, attr) VALUES
('A', 'Cloud Gate', 41.8826572, -87.6233039,
'{"category": "Landmark", "lastVisitDate": "11/10/2019"}');
Ahora a realizar las siguientes consultas:
- Obtén todos los campos de todos los registros de la tabla
- Obtén el nombre del restaurante y tipo de comida de todos los restaurantes
- Obtén el nombre del restaurante y la lista de especialidades (favorites) de todos los restaurantes
- Obtén el precio de la primera especialidad
MongoDB y Bson¶
Búsqueda¶
db.collection.find( <query>, <projection>, <options> )
Donde:
- query: filtramos filas
- projection: filtramos columnas
- options: límite, máximo, orden, ...
Fuente: Búsquedas en MongoDB
Ejercicio:¶
Vamos a jugar con Json en MariaDB gracias a OneCompiler
db.employees.insertMany([
{_id: 1, name: 'Clark', dept: 'Sales', age: 23 },
{_id: 2, name: 'Dave', dept: 'Accounting', age: 30 },
{_id: 3, name: 'Ava', dept: 'Sales', age: 25 }
]);
db.employees.insertOne( {name: 'Pedro', dept: 'Ingenieria', age: 44} );
db.employees.insertOne( {name: 'Maria', dept: 'Ingenieria'} );
- Obtén la lista de todos los empleados
- (query) Sólo del departamento ventas
- (proyection) Sólo la lista de nombres
- (proyection + filtros) Sólo los nombres y edades de los mayores de 23 años.
- (funciones) Obtén el más jóven
- y el más mayor.
Ejercicio¶
db.tienda.insertMany([
{_id:1, nombre:'Teclado', "codigo":101,"precio":1200,"tags":["periferico","gaming"]},
{_id:2, nombre:'Ratón',"codigo":102,"precio":850,"disponible":false},
{_id:3, nombre:'Monitor',"codigo":103,"precio":22000,"tamaño":[24,27]},
{_id:4, nombre:'Tarjeta SSD',"codigo":104,"precio":15000,"esNVMe":true}
]);
Resuelve:
- Muestra el nombre y precio de los productos almacenados
- Muestra sólo los que cuesten más de 1000 €
- Muestra sólo los que sean discos NVME (pista “esNVME” = true)
- Obten la lista de tamaños del producto ‘Monitor’
Json y APIs¶
Yaml¶
Sencillo, humano, ... sólo no uses tabuladores.
Es un formato que se crea inspirado en python para ser compatible con json y usable por humanos. Es 100 % compatible con Json y tenemos múltiples herramientas de conversión Json2yml y Yml2json.
Su utilización principal es ficheros de configuración, pero como json o xml podría ser empleado para serializar objetos.
- Aprende Yaml en Y minutos
- Validación de yaml con Yaml Linter
Ventajas de YML¶
- Comentarios
#: los comentarios no existen en otros archivos como json. - Multiples documentos en un archivo separándolos con
---. - Anclas
&y alias*(<<: *alias): ¿Algo se repite? Pues encapsulado con un ancla&partee invocado por su alias<<: *parte
# Documento1
uno: 1
dos: 2
---
# Documento2
# Definimos el ancla (lo común que queremos repetir)
x-cosa: &repe
a: juan
b: pedro
c: manolo
# Lo usamos por su alias:
uno:
<<: *repe
dos: a=juan b=pedro
tres:
<<: *repe
j: lola
cuatro:
<<: *repe
d: maria
Fuentes:
TOON¶
Lo nuevo: Versión 0.1 data de 22 de octubre de 2025
De:
{
"context": {
"task": "Our favorite hikes together",
"location": "Boulder",
"season": "spring_2025"
},
"friends": ["ana", "luis", "sam"],
"hikes": [
{
"id": 1,
"name": "Blue Lake Trail",
"distanceKm": 7.5,
"elevationGain": 320,
"companion": "ana",
"wasSunny": true
},
{
"id": 2,
"name": "Ridge Overlook",
"distanceKm": 9.2,
"elevationGain": 540,
"companion": "luis",
"wasSunny": false
},
{
"id": 3,
"name": "Wildflower Loop",
"distanceKm": 5.1,
"elevationGain": 180,
"companion": "sam",
"wasSunny": true
}
]
}
A estilo CSV:
context:
task: Our favorite hikes together
location: Boulder
season: spring_2025
friends[3]: ana,luis,sam
hikes[3]{id,name,distanceKm,elevationGain,companion,wasSunny}:
1,Blue Lake Trail,7.5,320,ana,true
2,Ridge Overlook,9.2,540,luis,false
3,Wildflower Loop,5.1,180,sam,true
Objetivo: reducir el consumo de tokens de las IA y por tanto reducir los costos.
Fuente: oficial toon-format
Comparativa¶
timeline
title Historia de formatos
1998 : XML
2001 : JSON : YAML
2013 : Toml
2025 : Toon
Modelo de examen¶
Desarrolla los siguientes apartados a partir del diagrama:
1. [1p] Crea el XML que lo describa.
2. [1p] Crea el DTD que lo estandarice.
3. [1p] Usando Xpath selecciona ...
4. [1p] Usando Xpath devuelve ...
5. [1p] Convierte a Json.
6. [1p] Convierte a Yml optimizando el archivo con alias
Partiendo de una tabla en MariaDB que
almacena todos ..., pero sólo ...:
7. [1p] Obtén todos los datos de ...
8. [1p] Obtén el … de todos ...
Partiendo de una colección en MongoDB que
almacena todos ..., pero sólo ...:
9. [1p] Obtén todos los datos de ...
10. [1p] Obtén los datos de ... de todos ...
Leyenda: root (amarillo), nodos (rojo), escalares (blanco), valores (azul), atributos (verde).
El examen es muy sencillo. No hay medios puntos. O está bien o está mal.
Tip: Podéis proponeros como ejercicio realizar una esquema cualquiera e intentar resolver el examen con dicho esquema.